This page lists datasets, analysis and visualization scripts, and web applications from Yosuke's research activities. I have been fortunate to be involved in research projects that produced resources for the community. Most of the resources listed here are products from research projects conducted in the Rivas Lab and the Bejerano Lab at Stanford University. Our use of generalist repository for scientific data sharing was featured by NIH’s Office of Data Science Strategy (ODSS).
We provide the polygenic risk score models computed for Testosterone described in the sex-specific genetic effects on biomarker manuscript.
Reference: Y. Tanigawa, E. Flynn, and M. A. Rivas, The snpnet polygenic risk score coefficients for Testosterone levels described in 'Sex-specific genetic effects across biomarkers'. figshare. Dataset. (2020). https://doi.org/10.6084/m9.figshare.12793490.v1
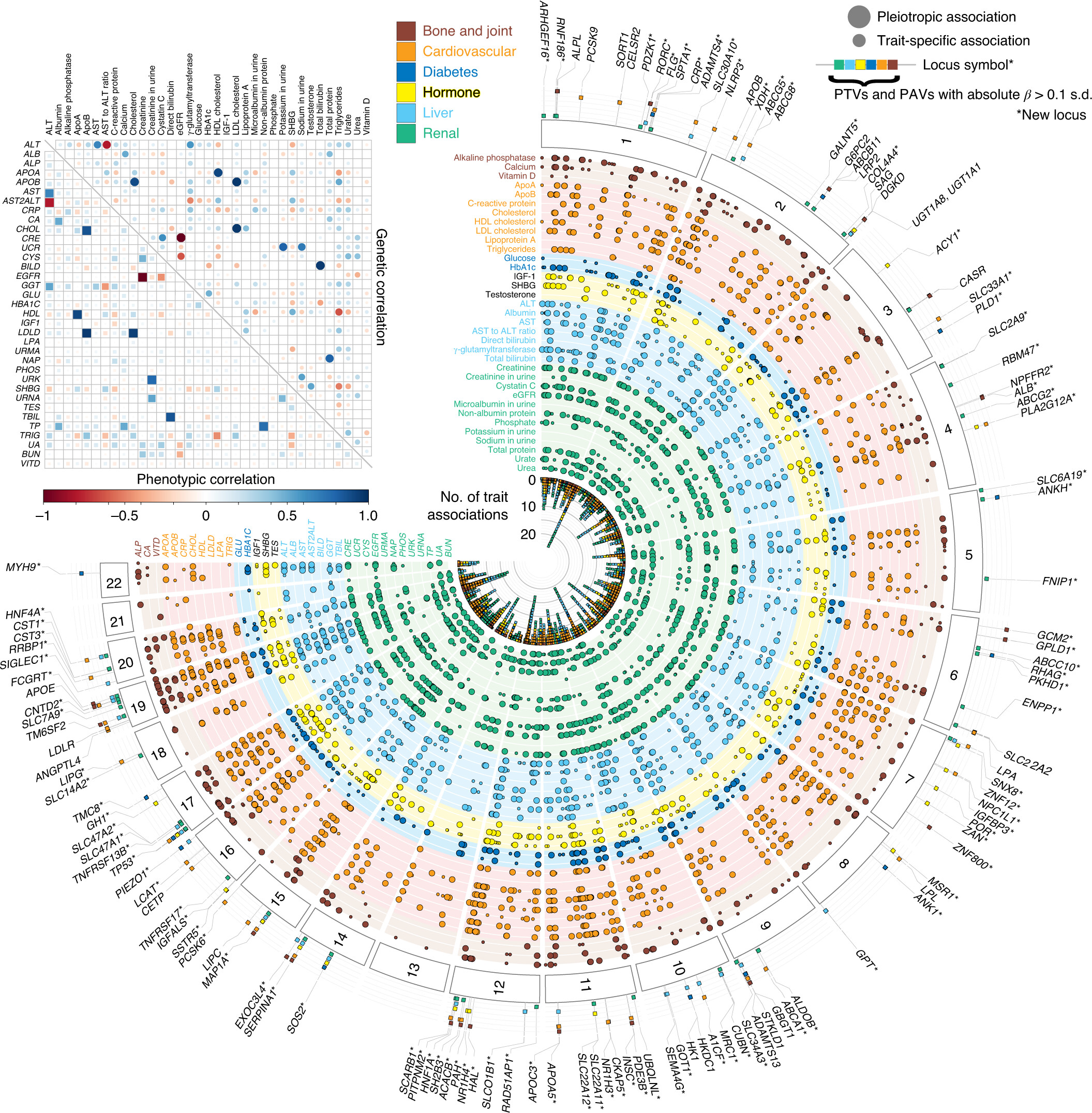
We provide datasets described in our biomarker manuscript.
Reference: Y. Tanigawa, N. Sinnott-Armstrong, C. Benner, and M. A. Rivas, Datasets described in 'Genetics of 35 blood and urine biomarkers in the UK Biobank'. National Institutes of Health. Collection. (2020). https://doi.org/10.35092/yhjc.c.5043872.v1
We provide datasets described in our ANGPTL7 paper.
Reference: Y. Tanigawa, and M. A. Rivas, Datasets described in 'Rare protein-altering variants in ANGPTL7 lower intraocular pressure and protect against glaucoma'. National Institutes of Health. Collection. (2020) https://doi.org/10.35092/yhjc.c.4990529.v1
As a part of the COVID-19 Host Genetics Initiative, we perform the following set of analyses to better understand the genetic basis of COVID-19 susceptibility and severity.
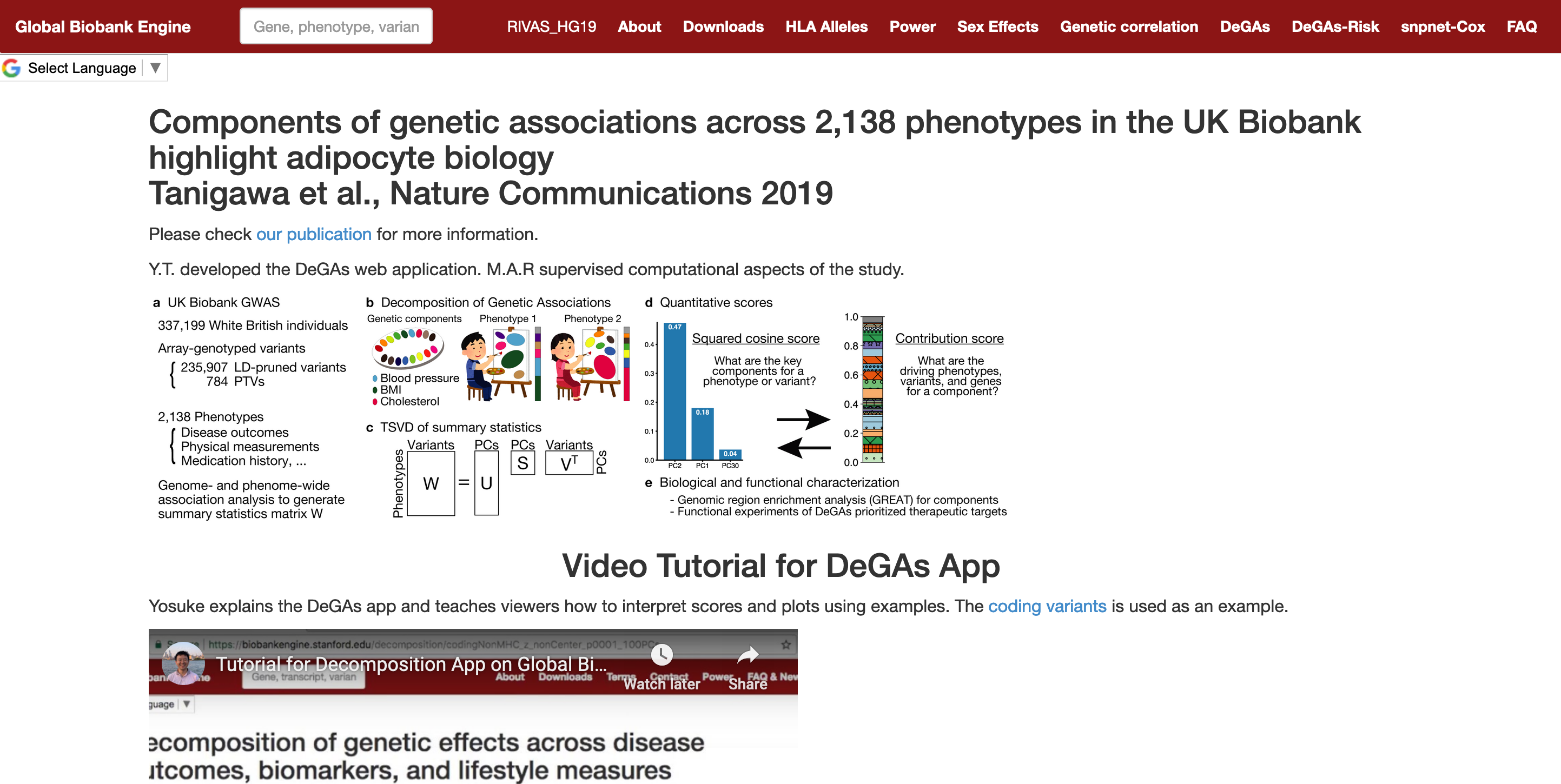
Reference: Y. Tanigawa, and M. A. Rivas, Decomposed matrices used for the analysis described in 'Components of genetic associations across 2,138 phenotypes in the UK Biobank highlight adipocyte biology'. (2019). https://doi.org/10.35092/yhjc.9202247.v1
As a resource accompanying our recent publication, we provide an interactive web application so that users can test DeGAs (decomposition of genetic associations).
We, the Rivas Lab, have aggregated summary statistics from population cohorts, originally from over 330,000 individuals from UK Biobank, and provide a browser and inference engine for the community. As of July 2020, our data now feature over 750,000 individuals across three cohorts: UK Biobank, Million Veterans Program and Biobank Japan.